AI agent red teaming is the enterprise security discipline that answers the one question every other control in your agentic AI security program cannot answer: do your defenses actually work? You can implement instruction hierarchy enforcement, tool permission scoping, behavioral monitoring, and supply chain provenance controls — and still not know whether those controls hold under real adversarial conditions until they are tested deliberately, by people who are trying to break them.
Only 26% of organizations conduct proactive security testing specific to AI systems, while 97% have already experienced GenAI-related security incidents. That gap — between the near-universal incidence of AI security incidents and the minority of organizations that test proactively — is the defining risk posture failure of enterprise AI adoption in 2026. Organizations are deploying AI agents into business-critical workflows, securing them with controls they have not validated, and discovering the gaps only when an incident forces the discovery.
As organizations increasingly deploy generative AI and autonomous agents into business-critical workflows, traditional application security practices are no longer sufficient. AI systems introduce new risk classes including prompt injection, model misuse, agent privilege escalation, data poisoning, hallucinations, and emergent behaviors that evolve continuously throughout the AI adoption lifecycle. Agentic red teaming provides a structured, lifecycle-wide approach to identifying, measuring, mitigating, and governing these risks through coordinated adversarial testing, defensive validation, and continuous feedback loops.
This pillar guide delivers the complete enterprise framework for AI agent red teaming: the methodology, the attack scope, the tooling landscape, the organizational structure, and the integration into development and governance pipelines that defines the 2026 standard for proactive agentic AI security validation.
Why AI Agent Red Teaming Is Fundamentally Different from Traditional Penetration Testing
Traditional penetration testing was built for a world of deterministic software. A penetration tester probes a defined attack surface — network perimeters, web application endpoints, authentication mechanisms, API boundaries — using known techniques against known vulnerability classes. The system under test behaves the same way every time for the same input. Vulnerabilities are reproducible, fixable, and verifiable through re-test.
AI agent red teaming operates in a fundamentally different environment. The system under test is non-deterministic — the same input can produce different outputs across multiple executions. The attack surface includes not just the software infrastructure but the model’s reasoning behavior, its response to natural language manipulation, its handling of adversarial content in retrieved context, its compliance with policy constraints under pressure, and its behavior when tools are invoked in unexpected sequences. Many of the most significant vulnerabilities in AI agents are not bugs in code — they are emergent behaviors that arise from the interaction between the model’s capabilities and the agent’s operational context.
Critically, AI agent red teaming must assess the agent’s behavior across its full operational scope, not just its boundary conditions. A wave of recent work points toward agent-orchestrated assessment, where an AI agent picks attacks, composes transforms, runs them against a target, and produces structured findings from a natural-language objective. Continuous AI assessment becomes practical when a single operator can run hundreds of attacks in an afternoon, changing procurement and staffing assumptions tied to annual or quarterly red team engagements.
Traditional penetration testing cadences — annual assessments, quarterly scans — are structurally inadequate for AI agent security because the agent’s attack surface changes continuously as model versions are updated, system prompts are modified, new tools are integrated, and the retrieval corpus expands. Effective AI agent red teaming must be continuous, automated where possible, and embedded in the agent development lifecycle rather than conducted as a periodic external exercise.
The AI Agent Red Teaming Scope: What to Test and Why
Defining the correct scope for AI agent red teaming is the foundational step that determines whether the exercise produces actionable findings or false assurance. The scope must cover five distinct vulnerability domains that together constitute the complete AI agent attack surface.
Domain 1: Goal Hijacking and Instruction Override
Goal hijacking attacks attempt to redirect the agent’s behavior away from its authorized objective toward attacker-specified objectives through manipulation of the instruction channel. Red teaming in this domain tests whether the agent’s instruction hierarchy — the priority ordering between system-level instructions, user inputs, and environmental content — holds under adversarial pressure.
Specific test scenarios include direct instruction override attempts in the user input channel, role assumption attacks that instruct the agent to adopt an identity with different constraints, nested instruction attacks that embed redirect commands within otherwise legitimate requests, and goal drift tests that introduce incremental steering across a multi-turn conversation to move the agent progressively away from its authorized operational scope.
The pass criterion for this domain is behavioral consistency: the agent should maintain its authorized objective and constraint set regardless of the content or phrasing of user inputs or environmental content. Deviations from authorized behavior under any tested condition represent findings requiring remediation before production deployment.
Domain 2: Prompt Injection and Environmental Manipulation
As documented in the AI agent prompt injection guide, this attack class embeds malicious instructions in content the agent retrieves and processes during normal task execution. Red teaming in this domain requires constructing realistic injection payloads in every content type the agent is likely to encounter — documents, emails, web pages, API responses, database records, tool outputs — and evaluating whether the agent executes the embedded instructions or correctly identifies and ignores them.
Advanced prompt injection red teaming scenarios include multi-stage injection chains — where an initial injection establishes a condition that a subsequent injection exploits — and cross-agent injection propagation tests in multi-agent orchestration architectures, where a successful injection in a subordinate agent is tested for propagation to orchestrating agents. These cascading injection scenarios represent the highest-severity finding class because their potential impact extends across the entire agent pipeline rather than a single agent instance.
Domain 3: Tool Misuse and Privilege Escalation
Agent tools represent the execution layer where AI behavior produces real-world consequences. Red teaming in this domain tests whether an adversary can manipulate the agent into invoking tools in unauthorized ways, exceeding the scope of its provisioned tool permissions, accessing systems outside its designated operational boundary, or chaining tool invocations to produce an outcome that no single tool call would achieve.
Traditional security testing was not built for generative AI. Prompt injection, jailbreaks, data leakage, and indirect attacks through retrieved context do not show up in SAST scanners or pen-test playbooks. That is why the AI red teaming category has exploded, with independent research forecasting the LLM security and observability market continuing to compound through 2029. Research And Markets
Privilege escalation test scenarios are particularly important for agents connected to the Model Context Protocol, where tool permissions may be broader than what specific task executions require. A red team finding that an agent can be manipulated into invoking a write tool during a task that should only require read access represents a least-privilege failure with direct operational risk implications.
Domain 4: Data Exfiltration and Information Leakage
Data exfiltration tests evaluate whether an adversary can manipulate the agent into revealing sensitive information it has access to but is not authorized to share — through the agent’s outputs, through tool calls to unauthorized destinations, or through side-channel information in the agent’s reasoning process. Information leakage tests specifically target system prompt disclosure, security constraint extraction, and tool catalog enumeration — the intelligence-gathering operations that precede more sophisticated attacks.
Red teaming in this domain requires constructing scenarios that resemble legitimate information requests sufficiently closely to pass initial intent filtering, while actually targeting sensitive information the agent should not reveal. Multi-turn extraction attacks — where each individual turn appears benign but the aggregate response set reveals sensitive content — are among the most common findings in this domain and among the most frequently missed by single-turn evaluation methodologies.
Domain 5: Denial of Service and Resource Exhaustion
Agentic AI systems with tool access to compute resources and external APIs present denial-of-service attack surfaces that traditional AI safety evaluations do not assess. Red teaming in this domain tests whether an adversary can manipulate the agent into executing resource-exhausting operations — infinite loop conditions in agent execution, recursive tool invocations, API call floods to external services, or storage exhaustion through excessive write operations.
Multi-agent denial-of-service attacks are a documented and rapidly evolving threat class. Multi-agent denial-of-service attacks succeeded in over 80% of tests in ACL 2025 research, and adversaries have adopted agentic tooling that scales campaigns and compresses dwell time. Testing the agent’s execution limits and the circuit-breaker controls that should interrupt runaway execution is a required component of the complete red teaming scope.
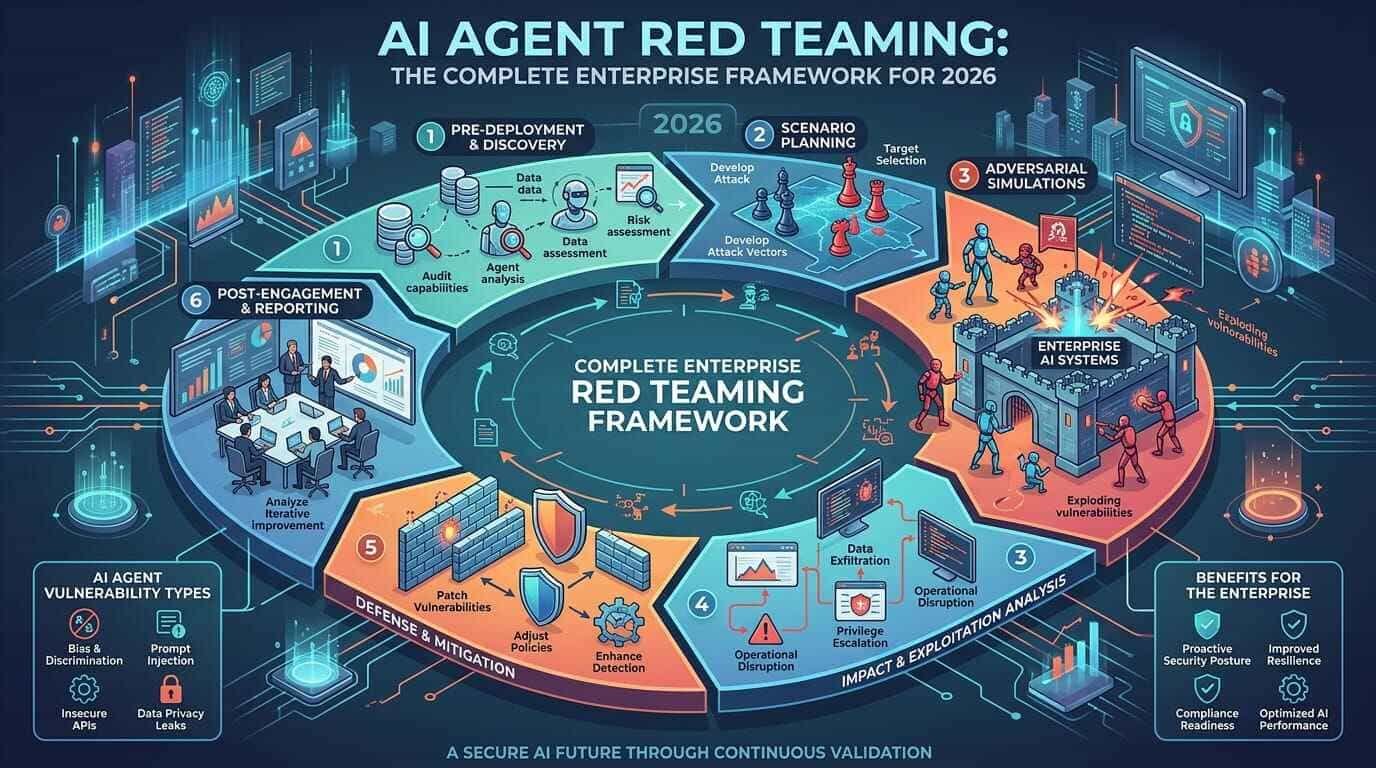
The AI Agent Red Teaming Methodology: A Structured Five-Phase Approach
Effective AI agent red teaming follows a structured methodology that moves from reconnaissance through exploitation to remediation validation. Each phase produces specific deliverables that inform the next phase and contribute to the final findings report.
Phase 1: Attack Surface Mapping and Threat Modeling
Before a single test is executed, the red team must construct a complete map of the agent’s attack surface. This mapping exercise documents every input channel the agent processes, every tool it has access to and the permissions those tools carry, every data source it retrieves from, every downstream agent or system that consumes its outputs, and every constraint that governs its authorized behavior.
Critically, attack surface mapping must include the agent’s operational context — the typical user interactions, the expected data sources, and the normal tool invocation sequences that define baseline behavior. Without a clear baseline, red team findings cannot be assessed for significance: a behavior that appears anomalous in the abstract may be normal for this specific agent’s operational context, while a behavior that appears routine may represent a significant deviation for this agent’s designated function.
The threat model produced in this phase prioritizes the identified attack vectors by consequence severity — the combination of the likelihood of successful exploitation and the impact of a successful attack on the organization’s operations, data, and regulatory position. This prioritization guides the test sequencing in subsequent phases to ensure that the highest-consequence findings are discovered first, even when time constraints prevent exhaustive testing.
Phase 2: Pre-Deployment Adversarial Testing
Pre-deployment red teaming targets the agent in a controlled environment before it reaches production, using the attack surface map and threat model from Phase 1 to guide structured adversarial testing across all five vulnerability domains.
Microsoft’s open-source RAMPART framework — released in April 2026 specifically for pre-deployment agent testing — provides a structured set of test cases for cross-prompt injection, behavioral regression detection, and data exfiltration scenarios. Combined with NVIDIA’s Garak framework for systematic LLM vulnerability scanning and Microsoft’s PyRIT for automated red teaming attack orchestration, pre-deployment testing can achieve coverage across the OWASP Top 10 for Agentic Applications that would require weeks of manual testing if conducted without tooling.
Findings from pre-deployment testing feed directly into the remediation cycle: control gaps identified before production deployment are addressed through design changes, configuration updates, and additional constraint implementation — at a fraction of the cost and risk of post-deployment remediation.
Phase 3: Production Red Teaming with Live System Validation
Pre-deployment testing in a controlled environment cannot fully replicate the attack surface of the production system, because production agents interact with real data, real tool integrations, and real user inputs that cannot be perfectly simulated in a staging environment. Production red teaming validates that the controls that performed correctly in pre-deployment testing hold under production conditions.
Production red teaming requires careful operational controls: coordinated timing to avoid generating false positive incidents in the production monitoring system, explicit authorization documentation that distinguishes red team activity from genuine attacks, and containment procedures that prevent red team test payloads from causing unintended operational impact. The AI agent observability infrastructure that supports production monitoring also provides the execution trace data that red team operators use to confirm whether test payloads were processed as expected and to reconstruct the agent’s complete response to each test scenario.
Phase 4: Automated Continuous Red Teaming Integration
Manual red teaming exercises — however thorough — produce a point-in-time assessment that begins to age the moment it is completed. Every model version update, system prompt modification, tool integration change, and retrieval corpus expansion potentially changes the agent’s security posture in ways that manual testing cannot continuously track.
Automated continuous red teaming integrates adversarial test cases into the CI/CD pipeline as release gate checks. Every deployment of an updated agent version automatically triggers a battery of adversarial tests before the deployment proceeds to production. Test cases that passed in the previous version but fail against the new version trigger a deployment halt and remediation requirement.
The tooling infrastructure for automated continuous red teaming in 2026 includes Confident AI’s adversarial testing platform, General Analysis’s production agent security platform, DeepTeam’s open-source red teaming framework, and Microsoft’s PyRIT — each offering different coverage profiles, automation levels, and integration patterns that should be evaluated against the organization’s specific agent architecture and CI/CD infrastructure.
Phase 5: Findings Reporting and Remediation Validation
Red teaming produces value only when its findings produce remediated systems. The findings report from an AI agent red teaming exercise must communicate findings in a format that is actionable for both technical teams responsible for implementation and governance stakeholders responsible for risk acceptance decisions.
Each finding should document: the attack scenario and the specific technique used to achieve it, the agent’s actual behavior in response to the attack, the expected behavior that the control should have produced, the consequence severity classification based on the operational impact of the demonstrated behavior, and the recommended remediation approach with implementation guidance.
Remediation validation — retesting the specific attack scenarios against the remediated system to confirm that the finding is resolved — is a required component of the findings lifecycle. Controls that appear to address a finding without resolving the underlying vulnerability produce a false assurance finding that is more dangerous than the original, because the remediation activity creates organizational confidence that the issue is resolved when it is not.
Tooling Landscape: AI Agent Red Teaming Platforms in 2026
The AI agent red teaming tooling landscape has matured rapidly in 2026, moving from experimental open-source frameworks to a structured set of platforms with specific coverage profiles and integration patterns. Understanding the tooling landscape is essential for building a red teaming program that delivers coverage without duplication.
Open-Source Frameworks
Microsoft PyRIT (Python Risk Identification Toolkit) is the most widely deployed open-source AI red teaming framework in enterprise environments, providing automated attack orchestration, configurable attack targets, and integration with Azure AI infrastructure. PyRIT covers jailbreaks, prompt injection variants, and multi-turn attack patterns with a plugin architecture that supports custom attack technique implementation.
NVIDIA Garak provides systematic vulnerability scanning with a generator-detector pipeline that can evaluate language models against hundreds of probe categories simultaneously, producing structured vulnerability reports that map findings to established risk taxonomies including the OWASP Top 10 for LLM Applications.
Microsoft RAMPART — open-sourced in April 2026 — specifically targets agentic deployments rather than base model evaluation, providing test cases for cross-prompt injection, behavioral regression detection, and data exfiltration scenarios that reflect the actual attack surface of production agent systems. Its release represents the most significant advancement in purpose-built agentic red teaming tooling to date.
DeepTeam offers an open-source red teaming framework with over 50 vulnerability types and 20 attack vectors covering both single-turn and multi-turn attack scenarios, with active community maintenance and a stable API surface that supports integration into existing security automation pipelines.
Commercial Platforms
General Analysis provides the most comprehensive automated red teaming suite for production agentic systems in 2026, mapping agents, prompts, tools, permissions, retrieval sources, and policies before launching adaptive adversarial campaigns against the real attack surface rather than against isolated model prompts. Its coverage of MCP-connected workflows, RAG systems, and multi-agent architectures makes it particularly relevant for the enterprise agentic AI deployments that represent the highest-consequence red teaming targets.
Confident AI combines automated adversarial testing covering over 50 vulnerability classes across the OWASP Top 10 and NIST AI RMF with LLM evaluation and observability in a single platform, providing coverage across the pre-deployment through production monitoring lifecycle.
Lakera, Mindgard, and Enkrypt each provide commercial platforms with specific coverage strengths in runtime guardrail validation, model security assessment, and compliance-aligned vulnerability reporting respectively.
Selecting the Right Tooling Stack
No single tool covers the complete AI agent red teaming scope. Effective enterprise programs typically combine an open-source framework (PyRIT or DeepTeam) for automated pre-deployment testing integrated into CI/CD, a purpose-built agentic platform (General Analysis or Confident AI) for comprehensive production agent assessment, and manual red teaming expertise for the high-consequence vulnerability classes that require human judgment to construct and evaluate realistic attack scenarios.
Integrating AI Agent Red Teaming with Enterprise Security Governance
AI agent red teaming produces maximum organizational value when its findings integrate with the broader enterprise security governance framework rather than existing as an isolated security exercise.
Integration with the Agentic AI Governance Framework
Red teaming findings directly inform the agentic AI governance framework risk classification process. Agents whose red teaming results reveal unacceptable vulnerability profiles should be reclassified to a higher risk tier — with the additional controls and human oversight requirements that higher risk tier demands — before production deployment proceeds. The governance framework provides the organizational context within which red team findings are assessed for risk acceptance or remediation; the red teaming program provides the empirical evidence that risk assessments require.
Integration with Non-Human Identity Security
Red teaming exercises should specifically test the non-human identity security controls that govern agent credentials and access. Privilege escalation test scenarios in the red teaming program directly validate whether the least-privilege principles and just-in-time access controls implemented in the NHI governance program actually constrain agent behavior under adversarial conditions. Red team findings that reveal privilege escalation paths represent NHI control gaps requiring remediation.
Integration with Supply Chain Security
AI agent red teaming should include supply chain attack simulation scenarios that validate the AI agent supply chain security controls. Specifically, red teamers should attempt to deliver malicious content through each supply chain vector — MCP server responses, retrieved documents, API payloads — to validate that content sanitization, provenance verification, and behavioral monitoring controls detect and block supply chain attack payloads under realistic conditions.
Integration with the CI/CD Pipeline as a Release Gate
The most operationally impactful integration is the implementation of red teaming as a CI/CD release gate: a set of automated adversarial tests that every new agent deployment must pass before reaching production. This integration ensures that security regression — the introduction of new vulnerabilities through development changes — is caught before production exposure rather than after.
Defining the specific pass/fail criteria for automated red teaming release gates requires balancing thoroughness against deployment velocity. A reasonable baseline for initial implementation includes zero critical findings (those demonstrating successful goal hijacking, data exfiltration, or privilege escalation), with a defined remediation SLA for high and medium findings before the deployment can proceed.
Building the Enterprise AI Red Teaming Program: Organizational Requirements
Technical tooling and methodology are necessary but insufficient for an effective AI agent red teaming program. The organizational requirements — team structure, skills, cadence, and governance integration — are equally important.
Team Structure and Skills
Effective AI agent red teaming requires a combination of skills that does not exist in any single traditional security role. The required competency set includes: deep understanding of LLM behavior and prompt engineering (to construct realistic and effective attack scenarios), traditional penetration testing methodology (to structure the assessment and document findings professionally), knowledge of the specific agent architecture being tested (to construct attacks that target the actual attack surface rather than hypothetical vulnerabilities), and familiarity with the regulatory and compliance context (to assess findings against applicable requirements).
Most organizations build their initial AI red teaming capability by extending existing penetration testing team skills with AI-specific training rather than hiring AI red teamers as a separate function. Microsoft’s PyRIT and RAMPART documentation, the OWASP Top 10 for Agentic Applications, and NIST’s CAISI red teaming guidance provide the foundational curriculum.
Cadence and Trigger Events
AI agent red teaming should occur on both a scheduled cadence and in response to specific trigger events. The scheduled cadence for production agents should be quarterly at minimum — though continuous automated testing should supplement manual quarterly assessments. Trigger events that should initiate an unscheduled red teaming exercise include: a significant model version update, a new tool integration or MCP server addition, a material change to the system prompt or agent configuration, a disclosed vulnerability in a component of the agent stack, and a security incident involving any agent in the deployment.
Findings Management and Risk Acceptance
Red team findings require a governance process for tracking, prioritization, remediation assignment, and risk acceptance decisions. Critical and high findings should be tracked in the organization’s existing vulnerability management system with assigned owners and remediation SLAs. Medium findings should be scheduled for remediation within the next development sprint. Low findings should be documented and reviewed quarterly for trend analysis.
Risk acceptance — the documented decision to deploy or maintain an agent with a known finding that has not been remediated — requires explicit sign-off from the appropriate governance authority at a level commensurate with the finding’s consequence severity. This risk acceptance process is a required component of the governance documentation that regulatory frameworks including the EU AI Act demand for high-risk AI deployments.
Strategic Outlook & Implementation
When auditing B2B SaaS architectures as a Digital Growth Specialist, my immediate focus on AI agent red teaming is always the same starting question: has anyone actually tried to break this agent, deliberately, using realistic attack scenarios? In every enterprise AI program I have reviewed in 2026, the honest answer is no. Security teams have reviewed the model vendor’s safety documentation. They have assessed the governance controls on paper. They have monitored production behavior through observability dashboards. But almost none of them have constructed an adversarial payload, delivered it to the agent through a realistic attack vector, and documented the agent’s response.
That gap — between knowing what your controls are supposed to do and knowing what they actually do under adversarial conditions — is where enterprise AI security programs are most vulnerable in 2026. The 97% GenAI incident rate is not a coincidence. It reflects the systematic absence of pre-deployment adversarial validation across an industry that has prioritized deployment velocity over security assurance.
My implementation recommendation follows a direct sequence. Start with a scoped, manual red teaming exercise against your highest-consequence production agent — the one with the broadest tool access and the most sensitive data exposure. Engage the red team with the full attack surface map and the explicit mandate to find something exploitable. Document every finding, regardless of severity. This first exercise will produce findings that surprise the engineering team, because they always do, and those findings will create the organizational urgency that makes the continuous red teaming program fundable.
Then build the CI/CD integration. Automated adversarial tests as a release gate are the single highest-leverage technical investment in an AI red teaming program. They cost a fraction of manual testing and they scale with agent deployment volume — the automated test battery does not grow in cost as the number of deployed agents grows. The manual quarterly assessment remains essential for finding the novel attack classes that automated testing does not yet cover, but the CI/CD gate ensures that known vulnerability classes are tested against every deployment automatically.
The organizations building AI agent red teaming into their development lifecycle today are building the security assurance infrastructure that will define competitive differentiation in enterprise AI deployment in 2027 and beyond. Customers, regulators, and boards are all asking the same question: have you tested this? The organizations that can answer yes — with documented methodology, findings, and remediation evidence — will earn the trust that scales AI program investment. Those that cannot will face increasing friction as regulatory requirements and enterprise procurement criteria mature.
Test your agents. Then fix what you find.
Frequently Asked Questions: AI Agent Red Teaming
Q1: How is AI agent red teaming different from standard LLM evaluation?
Standard LLM evaluation assesses model capability and alignment — does the model produce accurate, helpful, safe outputs across a defined evaluation dataset? AI agent red teaming assesses security vulnerability — can an adversary manipulate the agent into taking unauthorized actions, revealing sensitive information, or producing harmful outputs through realistic attack techniques? Evaluation datasets test representative expected inputs. Red teaming specifically constructs adversarial inputs designed to find failure modes. Both are necessary; neither substitutes for the other. An agent can score highly on capability evaluation while carrying exploitable vulnerabilities that red teaming reveals.
Q2: What is the minimum viable AI agent red teaming program for a small security team?
A minimum viable program for a resource-constrained team consists of three components: an automated pre-deployment test suite using an open-source framework (DeepTeam or PyRIT) integrated into the CI/CD pipeline as a release gate, a quarterly manual assessment of the highest-consequence production agent conducted by the security team with AI-specific training, and documented pass/fail criteria for the automated tests that define when a finding blocks deployment versus when it is accepted with documented risk. This baseline program addresses the most critical vulnerability classes — goal hijacking, prompt injection, and privilege escalation — with automation covering continuous regression detection and manual assessment covering the novel attack scenarios that automation does not yet reach.
Q3: Should AI agent red teaming be conducted internally or by an external team?
Both have distinct roles. Internal red teaming — conducted by the organization’s own security team — provides continuous coverage, deep familiarity with the agent’s intended design and authorized behavior, and rapid finding-to-remediation cycles. External red teaming — conducted by an independent team with no prior exposure to the agent — provides the fresh-eyes perspective that identifies assumptions and blind spots that internal teams have normalized. The practical recommendation is: implement internal continuous red teaming as the baseline program, and supplement with an annual external assessment that specifically challenges the assumptions built into the internal program’s test design.
Q4: How do I prioritize which agents to red team first when my organization has dozens of deployed agents?
Prioritize by the product of consequence severity and attack surface breadth. Consequence severity reflects the potential operational, regulatory, and reputational impact of a successful attack against the agent — agents with write access to production systems or access to sensitive personal data carry higher consequence severity than read-only informational agents. Attack surface breadth reflects the number and diversity of input channels the agent processes — agents that retrieve from external sources, process user-generated content, or consume outputs from other agents have broader attack surfaces than agents that only process controlled internal inputs. The intersection of high consequence severity and broad attack surface identifies the agents that represent the highest red teaming priority.
Q5: What regulatory frameworks require AI agent red teaming, and what evidence do they demand?
The EU AI Act does not use the term “red teaming” explicitly, but its requirement for high-risk AI systems to undergo accuracy, robustness, and cybersecurity testing before market deployment implies pre-deployment adversarial validation. The NIST AI Risk Management Framework’s Measure function explicitly includes adversarial testing as a risk measurement technique. The Biden Executive Order on AI (October 2023) mandated red teaming for frontier AI models, establishing red teaming as a recognized federal AI safety practice. For regulatory evidence, organizations should maintain: the red teaming methodology documentation, the attack scope definition, the full findings report with severity classifications, the remediation actions taken for each finding, and the remediation validation results confirming finding resolution. This documentation package satisfies the technical documentation requirements of both the EU AI Act and NIST AI RMF for organizations subject to those frameworks.
Conclusion
AI agent red teaming is not optional for enterprises serious about deploying autonomous AI systems in business-critical contexts. The 97% GenAI incident rate among organizations that have not proactively tested their AI systems is the empirical evidence of what happens when deployment velocity outpaces security validation. The 26% that do conduct proactive testing represent the organizations building the security assurance infrastructure that makes sustainable, trustworthy agentic AI deployment possible.
The methodology in this guide — five-domain attack scope, five-phase structured approach, tooling stack combining open-source automation with manual expertise, and governance integration connecting red team findings to the full enterprise security framework — provides the operational foundation for an enterprise AI agent red teaming program that scales with agent deployment growth and matures alongside the evolving threat landscape.
Critically, AI agent red teaming is not a one-time exercise. The agent’s attack surface changes with every model update, every tool integration, and every system prompt revision. The red teaming program must be continuous, automated where possible, and embedded in the development lifecycle as a release gate rather than conducted as a periodic external audit. Organizations that build that continuity into their security program now will maintain the security assurance visibility that reactive, periodic testing can never provide.
Test your agents before attackers do. Document what you find. Fix it. Then test again.
About the Author
Hi, I’m Waqas Raza. Over the last 20 years as a Finance Manager and Digital Growth Specialist, I’ve focused on scaling technical B2B SaaS properties and navigating complex architectures. My work sits at the intersection of enterprise finance, AI infrastructure strategy, and operational efficiency — helping organizations translate AI ambition into auditable, scalable, cost-effective outcomes. I write at Vitalora Life to share frameworks that enterprise leaders can apply immediately, not just read and file away.