The Complete Architecture Guide to Retrieval-Augmented Generation in 2026
RAG for enterprise is the foundational architecture pattern that determines whether your AI systems answer from reliable, current, proprietary data — or hallucinate from outdated training data. In 2026, every production enterprise AI deployment that requires grounded, auditable output depends on RAG as its core knowledge layer.
The case for RAG is structural, not optional. Foundation models — regardless of how capable — have a knowledge cutoff, no access to your internal systems, and no awareness of your proprietary data, recent regulatory changes, or current product inventory. RAG closes that gap by retrieving relevant information from your own knowledge sources at inference time and injecting it into the model’s context before generation. The result is an AI system that reasons over your data, not just its training data.
This guide covers the complete enterprise RAG architecture: its five core components, three architectural patterns, vector database selection criteria, the RAG vs fine-tuning decision framework, global total cost of ownership, compliance requirements across US, UK, EU, and Canadian markets, and how RAG integrates with Model Context Protocol (MCP) and agentic AI systems already deployed across your infrastructure.
What Is RAG for Enterprise? A Precise Architecture Definition
Retrieval-Augmented Generation (RAG) is an AI architecture pattern that combines two distinct capabilities: a retrieval system that queries an external knowledge store for relevant information, and a generation model (LLM) that uses that retrieved information to produce accurate, grounded responses. The term was introduced in a 2020 paper by Lewis et al. at Meta AI Research and has since become the dominant pattern for enterprise LLM deployment.
The operational definition relevant to enterprise architects: RAG is a runtime augmentation pattern in which an LLM’s effective knowledge is dynamically extended at inference time by retrieving relevant document chunks from an indexed knowledge store and injecting them into the model’s prompt context — enabling the model to generate responses grounded in current, proprietary, and domain-specific data without requiring model retraining.
Three properties make RAG strategically important for enterprise deployment:
- Grounding without retraining: RAG enables accurate, domain-specific AI output without the cost or latency of fine-tuning a model on proprietary data. The knowledge lives in a retrievable store, not baked into model weights.
- Auditability by design: Because every RAG response is generated from retrieved source chunks, the provenance of every output is traceable — a property required by EU AI Act Article 12, HIPAA audit requirements, and financial services compliance frameworks.
- Knowledge freshness: A RAG index can be updated continuously as source data changes. A fine-tuned model requires a new training run to reflect new information. For fast-moving enterprise data — pricing, policy, regulatory updates — RAG is the only operationally viable approach.
Why Enterprise AI Systems Fail Without RAG
The failure mode of deploying a foundation model without RAG is well-documented across enterprise AI programs that reached production in 2024-2025. The pattern is consistent: the model performs impressively on general knowledge tasks during evaluation, then produces confident, fluent, and factually incorrect outputs when asked about the organization’s own products, policies, processes, or recent events.
This is not a model quality problem. It is an architectural problem. Foundation models are not designed to know your company’s Q2 pricing changes, your updated compliance policy, or the contents of the support ticket filed three hours ago. Deploying them without retrieval augmentation and expecting domain-accurate output is the equivalent of hiring an expert consultant and withholding all company documentation before asking them to advise on internal strategy.
The four most common enterprise AI failures attributable to missing RAG infrastructure:
- Hallucinated policy outputs: Customer-facing AI assistants confidently stating incorrect product terms, warranty conditions, or compliance requirements — because the model is generating from training data, not live policy documents.
- Stale regulatory guidance: Legal and compliance AI tools producing guidance based on regulations as they existed at training cutoff — a critical failure in EU AI Act, GDPR, and financial services compliance contexts where regulatory updates are continuous.
- Data isolation failure: Enterprise search and knowledge management tools that cannot surface information from internal systems because no retrieval layer connects the LLM to proprietary knowledge stores.
- Audit trail absence: AI systems that produce outputs with no traceable source — a direct compliance failure under EU AI Act Article 12 logging requirements and under HIPAA for healthcare AI deployments.
RAG is not an enhancement to enterprise AI. It is the missing infrastructure layer that makes enterprise AI deployable, auditable, and trustworthy at the organizational scale required by compliance and governance frameworks.
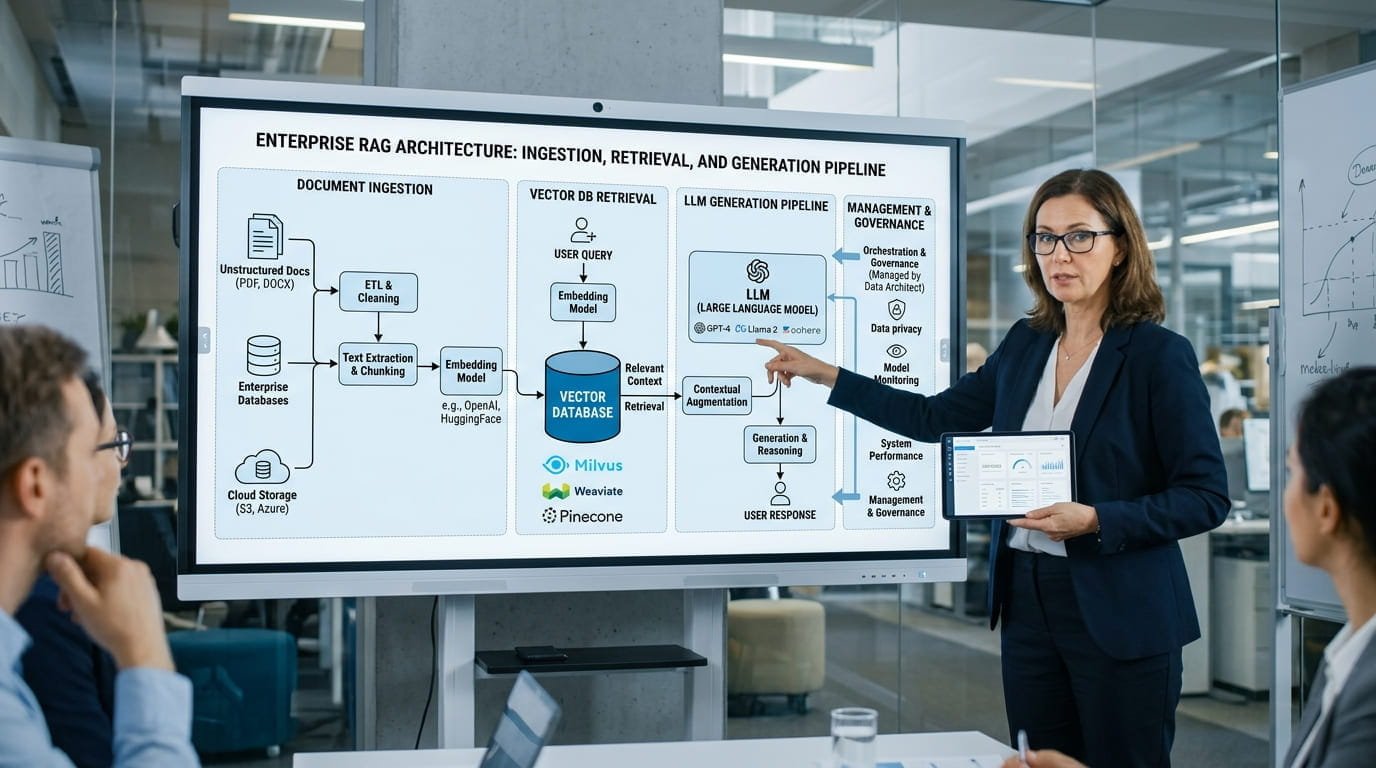
The 5 Core Components of Enterprise RAG Architecture
Component 1: Document Ingestion and Chunking Pipeline
The ingestion pipeline is the data preparation layer of a RAG system — responsible for acquiring source documents, preprocessing them into clean text, splitting them into optimal chunks, and routing them for embedding and indexing. The quality of this pipeline directly determines retrieval precision; poor chunking strategies are the most common root cause of RAG retrieval failures in enterprise deployments.
Enterprise ingestion pipelines must handle heterogeneous source formats: PDF documents, Word files, SharePoint pages, Confluence wikis, database records, API responses, and structured JSON. Each format requires specific extraction logic to preserve semantic coherence through the conversion to plain text.
Chunking strategy is the most consequential ingestion decision. The three primary approaches:
- Fixed-size chunking: Splits text into uniform character or token windows (e.g., 512 tokens with 50-token overlap). Fast and simple, but often splits semantic units mid-sentence, degrading retrieval precision.
- Semantic chunking: Splits at natural semantic boundaries — paragraph breaks, section headers, topic shifts — preserving the coherence of each chunk. Higher computational cost, significantly better retrieval quality for enterprise document types.
- Hierarchical chunking: Maintains both summary-level and detail-level chunks for the same content, enabling multi-granularity retrieval. Best practice for long-form enterprise documents (legal contracts, technical specifications, regulatory filings).
For enterprise deployments, semantic or hierarchical chunking is strongly preferred. The marginal computation cost is negligible relative to the retrieval quality improvement.
Component 2: Embedding Models and Vector Representation
An embedding model converts each text chunk into a high-dimensional numerical vector — a dense mathematical representation of the chunk’s semantic meaning. Semantically similar text chunks produce vectors that are geometrically close in the embedding space, enabling similarity-based retrieval.
The selection of embedding model is one of the highest-leverage decisions in RAG architecture. Embedding model quality directly determines how accurately the retrieval system can match a user query to relevant knowledge chunks. Key selection criteria for enterprise contexts:
- Domain alignment: General-purpose embedding models (OpenAI text-embedding-3-large, Cohere Embed v3) perform well on broad knowledge retrieval. Domain-specific or fine-tuned embeddings outperform on specialized corpora (legal, medical, financial). Enterprises with highly specialized document types should evaluate domain-adapted models.
- Multilingual support: Enterprises operating across EU, UK, US, and Canadian markets with multilingual documentation require embedding models with strong multilingual performance (e.g., Cohere Embed Multilingual, multilingual-e5-large).
- Data sovereignty: For enterprises subject to EU data residency requirements or UK GDPR data transfer restrictions, embedding generation must occur within the compliant infrastructure boundary. Self-hosted embedding models (via Hugging Face) may be required for regulated data corpora.
Component 3: Vector Database and Index Management
The vector database stores the embedding vectors alongside their associated text chunks and metadata, and provides the similarity search infrastructure that powers retrieval. In production enterprise RAG, the vector database is the most operationally intensive component — requiring ongoing index management, freshness monitoring, and access control.
Enterprise vector database selection criteria:
| Database | Deployment | Best For | GDPR/Data Residency |
| Pinecone | Managed cloud | High-throughput, production RAG | EU region available |
| Weaviate | Self-hosted or managed | GDPR-sensitive, complex metadata filtering | Full self-host option |
| Qdrant | Self-hosted or cloud | High performance, EU data sovereignty | Full self-host option |
| pgvector | PostgreSQL extension | Orgs already on Postgres, low ops overhead | Inherits Postgres setup |
| Chroma | Self-hosted | Development, small-scale RAG | Not production-grade |
| Azure AI Search | Managed (Azure) | Microsoft ecosystem enterprises | EU region available |
For EU and UK enterprises with strict data residency requirements, self-hosted Weaviate or Qdrant running within compliant infrastructure boundaries is the recommended approach. Managed cloud options require verification that data processing agreements (DPAs) and Standard Contractual Clauses (SCCs) are in place.
Component 4: Retrieval Engine and Ranking Layer
The retrieval engine executes the similarity search: given a user query, it generates an embedding of the query, searches the vector index for the closest matching document chunks, and returns the top-k results for injection into the LLM context.
Basic vector similarity retrieval (dense retrieval) works well for semantic queries but has known weaknesses: it can miss exact keyword matches and struggles with highly specific technical queries where precise terminology matters. Enterprise RAG systems increasingly use hybrid retrieval — combining dense vector search with sparse keyword search (BM25) — to capture both semantic relevance and lexical precision.
Beyond raw retrieval, production enterprise RAG requires a re-ranking layer: a cross-encoder model or reranking service that evaluates the retrieved chunks against the original query with higher precision and reorders them before context injection. Reranking consistently improves retrieval quality by 15-30% in enterprise evaluations and is considered production best practice for high-stakes use cases.
Component 5: Augmentation, Generation, and Output Guardrails
The final component takes the retrieved chunks, constructs an augmented prompt that combines the user query with the retrieved context, and submits it to the LLM for generation. The quality of prompt construction at this stage — how retrieved chunks are formatted, ordered, and presented to the model — materially affects generation quality.
Enterprise production requirements at this layer include: context window management (ensuring retrieved chunks plus system prompt fit within the model’s context limit), source citation injection (enabling the model to reference specific source documents in its output), and output guardrail enforcement (safety classification, format validation, PII detection in outputs before delivery to end users or downstream systems).
The output layer also generates the evaluation signals required for LLMOps monitoring — faithfulness scores, answer relevance scores, and source attribution quality — which feed back into the RAG quality management loop described in Vitalora’s enterprise LLMOps guide.
RAG Architecture Patterns: Naive, Advanced, and Modular
Naive RAG: The Starting Point
Naive RAG is the simplest implementation: ingest documents, embed chunks, store in vector database, retrieve top-k on query, inject into prompt, generate. Most enterprise RAG proof-of-concepts begin here. Naive RAG produces acceptable results for simple knowledge retrieval tasks over well-structured, homogeneous document collections.
Naive RAG fails in production enterprise contexts for predictable reasons: retrieval precision is insufficient for complex multi-faceted queries, there is no query understanding or reformulation, retrieved chunks lack coherence when pulled from different document sections, and there is no mechanism to handle queries that span multiple knowledge domains.
Advanced RAG: Production-Grade Patterns
Advanced RAG addresses the failure modes of naive RAG through pre-retrieval and post-retrieval enhancements that are now considered standard practice for enterprise deployments:
- Query transformation: Before retrieval, the user’s query is rewritten, decomposed, or expanded to improve retrieval performance. HyDE (Hypothetical Document Embeddings) generates a hypothetical answer to the query and uses it as the retrieval query — significantly improving recall on complex questions.
- Multi-query retrieval: The original query is reformulated into multiple variants, each used to retrieve a distinct set of relevant chunks. Results are merged and deduplicated, improving coverage for queries that can be expressed multiple ways.
- Contextual compression: After retrieval, retrieved chunks are compressed to extract only the portions directly relevant to the query — reducing context window consumption and improving generation quality by removing noise.
- Self-RAG: The LLM itself decides when retrieval is needed, generates retrieval queries, evaluates retrieved chunks for relevance, and critiques its own output against retrieved evidence. Produces highest quality outputs but requires significantly more inference compute.
Modular RAG: The Enterprise Architecture Standard
Modular RAG deconstructs the RAG pipeline into interchangeable, independently configurable modules — search, memory, fusion, routing, predict, task adaptation — that can be combined and customized for specific enterprise use cases. This is the architecture pattern used by mature enterprise RAG deployments in 2026.
The key advantage of modular RAG for enterprise contexts is that different knowledge domains, user roles, and query types can be served by different pipeline configurations without rebuilding the entire system. A legal compliance query might route through a hybrid retrieval module with legal corpus priority and a reranking layer, while a product FAQ query routes through a simpler dense retrieval path with higher throughput priority.
RAG vs Fine-Tuning: The Enterprise Decision Framework
The most common strategic question enterprise AI teams face when deploying domain-specific LLM applications is whether to use RAG, fine-tuning, or both. The answer is not universal — it depends on the nature of the knowledge, the update frequency of the data, the compliance requirements, and the acceptable latency.
| Decision Factor | Use RAG | Use Fine-Tuning | Use Both |
| Knowledge update frequency | Frequent (daily/weekly) | Rare (stable domain knowledge) | Stable patterns + live data |
| Knowledge type | Factual, retrievable documents | Behavioral, stylistic, structural | Complex domain tasks |
| Auditability requirement | High (source traceable) | Low (baked into weights) | Compliance-critical apps |
| Data volume | Any (external index) | Large labeled dataset required | Both available |
| Infrastructure cost | Lower (no training compute) | High (GPU training runs) | Highest |
| Time to deploy | Days to weeks | Weeks to months | Months |
| Hallucination risk | Lower (grounded in retrieval) | Higher for factual tasks | Lowest overall |
For the majority of enterprise use cases — knowledge management, customer support, regulatory compliance, internal search, document Q&A — RAG alone is the appropriate architecture. Fine-tuning adds value when the enterprise requires the model to adopt a specific reasoning style, response format, or domain-specific behavior that cannot be achieved through prompt engineering. The combination of both is reserved for high-complexity, high-stakes applications where accuracy requirements justify the infrastructure investment.
Enterprise RAG Total Cost of Ownership: Global Benchmark
Understanding the full financial commitment of enterprise RAG requires a complete TCO model beyond API and infrastructure pricing. The following benchmarks represent mid-scale enterprise RAG deployments serving 10,000-50,000 users with 50,000-150,000 daily queries. All figures presented in USD ($), GBP (£), and EUR (€).
| Cost Component | US ($) | UK (£) | Europe (€) |
| Embedding API or self-hosted compute | $8,000–$24,000 | £6,400–£19,200 | €7,200–€21,600 |
| Vector database (managed or self-hosted) | $12,000–$48,000 | £9,600–£38,400 | €10,800–€43,200 |
| LLM generation API (retrieval-augmented) | $36,000–$120,000 | £28,800–£96,000 | €32,400–€108,000 |
| Ingestion pipeline infrastructure | $6,000–$18,000 | £4,800–£14,400 | €5,400–€16,200 |
| Reranking service | $4,000–$12,000 | £3,200–£9,600 | €3,600–€10,800 |
| Engineering allocation (0.5–1 FTE) | $75,000–$150,000 | £60,000–£120,000 | €67,500–€135,000 |
| Evaluation & monitoring tooling | $12,000–$36,000 | £9,600–£28,800 | €10,800–€32,400 |
| TOTAL annual TCO | $153,000–$408,000 | £122,400–£326,400 | €137,700–€367,200 |
RAG significantly reduces LLM generation costs compared to non-RAG deployments: by grounding queries in retrieved context, RAG reduces the average prompt length required to elicit accurate responses, and by filtering irrelevant queries before they reach the most expensive generation model, a RAG layer with model routing can reduce raw API spend by 30-50% relative to a direct LLM deployment at equivalent accuracy.
RAG Integration with MCP and Agentic AI Systems
For enterprises deploying agentic AI systems connected via Model Context Protocol (MCP), RAG is not a standalone deployment — it is the knowledge retrieval substrate that agentic workflows call when they require access to enterprise knowledge. The integration pattern is architecturally clean and increasingly standardized.
In an MCP-connected enterprise AI architecture, RAG knowledge bases are exposed as MCP tools — callable resources that an AI agent can query as part of its reasoning workflow. When an agent processing a procurement request needs to verify supplier compliance terms, it calls the RAG MCP tool for the contracts knowledge base, retrieves the relevant clauses, and incorporates them into its decision context. The entire retrieval and augmentation process is transparent in the agent’s trace, maintaining the auditability properties of RAG while extending them to agentic execution contexts.
This integration pattern is covered in depth in Vitalora’s Model Context Protocol enterprise guide 2026 and connects directly to the bounded autonomy frameworks discussed in the agentic AI safety architecture content. RAG gives agents access to accurate, current knowledge; MCP provides the standardized interface for that access; and LLMOps governance ensures the retrieval quality, cost attribution, and compliance logging are maintained across every agent interaction.
RAG Compliance: GDPR, EU AI Act, UK GDPR, and HIPAA
GDPR and UK GDPR
Enterprise RAG systems that index personal data of EU or UK data subjects must comply with GDPR and UK GDPR data minimization, purpose limitation, and storage limitation principles. The key operational implication: personally identifiable information should not be present in RAG indexes unless there is a documented lawful basis for processing and appropriate access controls are in place. Data subject rights — specifically the right to erasure (Article 17 GDPR) — must be operable at the RAG index level: if a data subject requests deletion, their personal data must be removable from the vector index as well as from the source systems.
For EU enterprises, RAG infrastructure running on US-hosted cloud services (Pinecone, OpenAI embeddings) requires Standard Contractual Clauses (SCCs) or Binding Corporate Rules (BCRs) as the legal transfer mechanism for personal data flowing to the embedding API or vector store. Self-hosted RAG infrastructure within EU boundaries eliminates this transfer compliance burden and is increasingly the chosen architecture for regulated industries in Germany, France, and the Netherlands.
EU AI Act Compliance
RAG systems deployed in high-risk AI application contexts under the EU AI Act (fully effective August 2026) must meet Article 12 logging requirements: the RAG system must maintain logs of retrieved source chunks and generation inputs sufficient to reconstruct the basis for any AI output for at least six months. This is architecturally straightforward — most production RAG platforms log traces at the chunk level — but must be explicitly designed into the system, not added retrospectively. Organizations failing to maintain this logging face penalties reaching €15M / £13M / $16.5M or 3% of global annual turnover.
HIPAA (US Healthcare)
Healthcare RAG systems processing Protected Health Information (PHI) must ensure that both the embedding pipeline and the vector database operate within HIPAA-eligible infrastructure with Business Associate Agreements (BAAs) in place for all service providers. PHI must not be transmitted to embedding APIs without BAA coverage. Self-hosted embedding models and vector databases within HIPAA-compliant cloud environments (AWS GovCloud, Azure Government) are the established approach for healthcare RAG deployments.
External authority: Meta AI Research’s original RAG paper (Lewis et al., 2020) at arxiv.org/abs/2005.11401 provides the foundational academic basis for RAG architecture. LlamaIndex documentation at docs.llamaindex.ai provides the most comprehensive enterprise RAG implementation reference currently available.
Strategic Outlook & Financial ROI
Expert Analysis by Waqas Raza — Finance Manager & Digital Growth Consultant (20 Years Experience)
The financial argument for enterprise RAG investment in 2026 is, at its core, an argument about stranded AI spend. The organizations I advise that deployed foundation model integrations in 2024 without retrieval augmentation have spent 12-18 months discovering a consistent truth: the cost of the generative AI infrastructure is not the dominant cost — the cost of the outputs being wrong is. In financial services, a compliance assistant that hallucinates regulatory guidance generates legal exposure that can exceed the annual operating cost of the entire AI program in a single incident. In healthcare, a clinical decision support tool that generates advice from stale training data rather than current clinical guidelines generates liability that no technology budget can absorb. RAG eliminates the architectural root cause of those failures — not by making models smarter, but by giving them access to the right information at the right time.
From a capital allocation perspective, RAG is one of the few enterprise AI investments where the cost avoidance case is quantifiable before deployment. For a mid-scale deployment with $120,000 / £96,000 / €108,000 in annual generation API costs, a well-architected RAG layer with model routing and semantic caching typically reduces that figure by 35-45% — a $42,000-$54,000 / £33,600-£43,200 / €37,800-€48,600 annual saving that alone can fund the entire RAG infrastructure investment. Stack the compliance incident avoidance value — particularly relevant for EU-regulated enterprises facing AI Act enforcement — and the ROI case for RAG becomes among the strongest in the enterprise technology portfolio. I have yet to work with an organization that implemented RAG rigorously and subsequently questioned whether the investment was justified. The question enterprises should be asking is not whether to invest in RAG, but how quickly they can operationalize it.
Macro-directionally, the enterprises building RAG infrastructure in 2026 are making the foundational investment that enables every subsequent AI capability — agentic workflows, AI-native search, autonomous decision support, compliance automation — to operate on accurate, current, proprietary knowledge rather than general training data. RAG is not a feature to be added to an AI system; it is the knowledge layer on which enterprise AI runs. Organizations that treat it as an infrastructure investment rather than a project deliverable will build the compounding advantage that distinguishes durable AI-native operations from expensive AI experiments.
Frequently Asked Questions
Q1: What is the difference between RAG and fine-tuning, and which should an enterprise choose?
RAG and fine-tuning solve different problems. RAG stores knowledge in an external index and retrieves it at inference time — making it the right choice for frequently updated data, proprietary documents, and any use case requiring a traceable source for every output. Fine-tuning bakes behavioral or structural patterns directly into model weights, which suits stable domain knowledge where a specific reasoning style or response format is needed. For the majority of enterprise use cases — compliance assistance, internal search, customer support, document Q&A — RAG alone is the preferred architecture because it maintains knowledge freshness without requiring a new training run and makes every output auditable by design.
Q2: Why does naive RAG fail in production, and when does an enterprise need advanced RAG?
Naive RAG — a straightforward ingest-embed-retrieve-generate pipeline — works acceptably for simple queries over well-structured, homogeneous document collections. It breaks down in production when queries are complex or multi-faceted, because basic chunking pulls incoherent fragments from different document sections and there is no query understanding or reformulation. Advanced RAG addresses this through query transformation techniques like HyDE, multi-query retrieval, contextual compression, and a reranking layer — which consistently improves retrieval quality by 15–30% in enterprise evaluations. For any deployment producing high-stakes outputs in compliance, financial, or customer-facing contexts, advanced RAG is the minimum production standard.
Q3: How should an enterprise choose a vector database for its RAG deployment?
Vector database selection should follow chunking strategy decisions, not precede them. The primary enterprise selection criteria are data residency compliance, operational overhead, and retrieval throughput. For EU and UK enterprises with strict data residency requirements, self-hosted Weaviate or Qdrant within compliant infrastructure boundaries eliminates cross-border data transfer obligations entirely. Pinecone suits high-throughput managed deployments where data residency is not a constraint. pgvector is the lowest-overhead option for organizations already running PostgreSQL. Chroma is suitable only for development and should not be treated as production-grade.
Q4: What are the EU AI Act compliance obligations for enterprise RAG systems?
Under EU AI Act Article 12, fully effective August 2026, enterprises deploying RAG in high-risk AI application contexts must maintain logs of retrieved source chunks and generation inputs sufficient to reconstruct the basis of any AI output for a minimum of six months. This needs to be explicitly designed into the system architecture — not added retrospectively. Under GDPR, personal data of EU data subjects should only be present in RAG indexes with a documented lawful basis, and the right to erasure under Article 17 must be operable at the vector index level, not only at source systems. Non-compliance penalties reach €15M or 3% of global annual turnover.
Q5: What is the financial ROI case for enterprise RAG investment?
For a mid-scale deployment with $120,000 / £96,000 / €108,000 in annual generation API costs, a well-architected RAG layer with model routing and semantic caching typically reduces that figure by 35–45% — a saving of $42,000–$54,000 / £33,600–£43,200 / €37,800–€48,600 annually that alone can fund the entire RAG infrastructure investment. The full annual TCO for mid-scale deployments (10,000–50,000 users) ranges from $153,000–$408,000 / £122,400–£326,400 / €137,700–€367,200, with engineering allocation as the dominant cost component. When compliance incident avoidance value is factored in — particularly relevant for EU-regulated enterprises facing AI Act enforcement — the ROI case for RAG is among the strongest in the enterprise technology portfolio.
Conclusion
RAG for enterprise is the architectural pattern that closes the gap between what foundation models know and what enterprise operations require them to know. Its five core components — ingestion, embedding, vector storage, retrieval, and augmented generation — form a complete knowledge pipeline that grounds every LLM output in current, proprietary, auditable enterprise data.
For organizations already operating agentic AI systems, MCP-connected tool networks, or LLM-powered workflows, RAG is not an optional enhancement. It is the knowledge substrate that makes those systems accurate enough to trust, current enough to rely on, and auditable enough to deploy in regulated contexts across US, UK, EU, Canadian, and global enterprise markets.
The architecture patterns, vector database selection criteria, RAG vs fine-tuning decision framework, and compliance requirements in this guide provide a complete foundation for enterprise RAG planning regardless of current deployment maturity. The ingestion pipeline is the appropriate starting point for most organizations — the returns on retrieval precision compound through every downstream component.
Ground your AI in your data. Everything else follows from there.
LlamaIndex Enterprise RAG Documentation: docs.llamaindex.ai