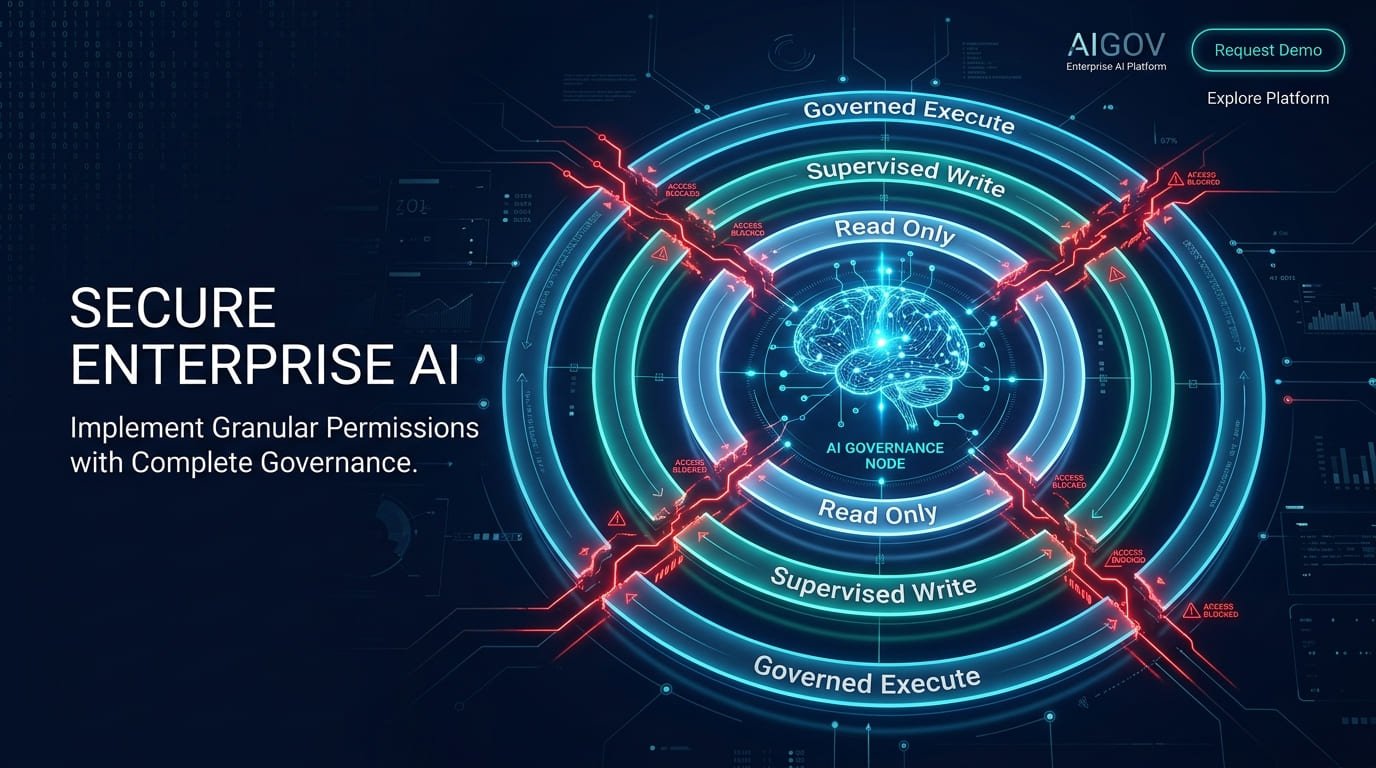
Bounded autonomy AI is the architectural principle that separates enterprise-grade agentic deployments from organizational liability. As AI agents move from isolated pilots into production systems that place purchase orders, modify databases, trigger downstream workflows, and interact with customers autonomously, the foundational engineering question is no longer how to make agents more capable — it is how to define the precise operational perimeter within which those capabilities are permitted to act.
The 2026 enterprise AI landscape has made this question urgent. Gartner projects that 40% of enterprise applications will embed AI agents by the end of 2026, up from less than 5% in 2025. The global agentic AI market, valued at $7.8 billion today, is forecast to reach $52 billion by 2030. A 2026 joint cybersecurity guidance document — co-authored by leading national security agencies — specifically identified privilege design, behavioral monitoring, structural accountability, and human oversight as the four priority risk domains in agentic AI deployments. NIST’s AI Agent Standards Initiative frames secure agentic systems around the same principles.
Yet the deployment reality is alarming. A 2026 joint agentic AI guidance report highlights that most organizations are granting AI agents write-access to production systems, API credentials, and customer data without the deterministic guardrails required to constrain unauthorized actions. A single misconfigured agent permission in a financial services firm is not a software bug — it is a regulatory event. In healthcare, it is a patient safety incident. In any enterprise, it is the kind of incident that converts an AI investment into an enterprise risk management crisis.
This guide provides the complete bounded autonomy AI architecture framework: the trust tier model, the least privilege principle applied to AI systems, the kill switch architecture, human-in-the-loop design patterns, observability requirements, and the enterprise governance overlay that makes safe agentic systems operational rather than theoretical.
▶ [See our Enterprise AI Governance Architecture Framework]
| 40% of enterprise apps will embed AI agents by end of 2026 — Gartner | $52B Agentic AI market forecast by 2030 from $7.8B today | 4 Priority risk domains in 2026 joint national security agentic AI guidance |
What Is Bounded Autonomy AI and Why It Defines the 2026 Architecture Debate
Bounded autonomy AI means hard-coding deterministic guardrails around probabilistic AI models. It is the architectural discipline of ensuring that AI agents operate within strict, unbreakable operational perimeters — using zero-trust design, least-privilege permissions, and human-in-the-loop approval gates to prevent unauthorized, unintended, or cascading actions.
The definition carries a critical technical implication. AI models are probabilistic systems — they generate outputs based on learned distributions, not deterministic rules. A probabilistic model will occasionally produce outputs outside the expected range, no matter how well it has been trained. Bounded autonomy addresses this not by making the model more certain, but by building deterministic constraints around it that prevent low-probability failure cases from becoming high-consequence incidents.
| The Core Principle of Bounded Autonomy AI You cannot make a probabilistic model perfectly safe. You can make the consequences of its errors perfectly bounded. Bounded autonomy AI is the architecture of consequence limitation — not capability limitation. |
This distinction matters enormously for enterprise architects and executives evaluating agentic AI deployments. Organizations that conflate model safety with deployment safety are making a category error. A model that performs well on benchmarks can still cause catastrophic enterprise harm if deployed without architectural constraints. Bounded autonomy AI addresses deployment safety — the layer between model capability and real-world consequence.
▶ [2026 Joint Cybersecurity Guidance on Agentic AI — cisa.gov]
Why Implementing Bounded Autonomy AI Fails — The Four Structural Mistakes
The April 2026 analysis published by AI Dev Day India identifies the failure pattern with uncomfortable precision: organizations understand bounded autonomy as a concept but fail to implement it as an architecture. The result is the illusion of safety — governance documentation that describes constraints which the actual deployed system does not enforce. Four structural mistakes account for most implementation failures.
Mistake 1 — Treating API Access as Binary
The most common failure is granting AI agents full API access to a system when the agent’s actual task requires only a subset of that system’s capabilities. If an agent needs to read customer records to generate a support response, giving it write access to those records is not a convenience — it is an unmanaged risk. Every additional permission granted beyond task necessity is an additional attack surface and an additional failure mode. The principle of least privilege, foundational in cybersecurity for decades, must be applied with equal rigor to AI agent permissions.
The practical implementation: never give an LLM direct database credentials. Route all requests through an intermediate middleware API that enforces schema-level read-only permissions as a hard technical constraint — not as a policy that the model is instructed to follow. Policy instructions can be overridden by adversarial prompts, jailbreaks, or model hallucinations. Hard technical constraints cannot.
Mistake 2 — Relying on Model Instructions for Safety
System prompt instructions are not security controls. An instruction that tells an agent “never modify production data” is useful context — it is not an enforcement mechanism. Bounded autonomy AI architecture must enforce critical constraints at the infrastructure layer, not the prompt layer. Instructions can be ignored, overridden by subsequent user prompts, or bypassed by adversarial injection. Infrastructure constraints — API permission scoping, write-lock mechanisms, sandbox isolation — cannot be overridden by anything the model generates.
Mistake 3 — Ignoring Rate and Cost Loop Risks
Even a perfectly safe agent in terms of data access can cause catastrophic operational harm through resource exhaustion. An agent entering an infinite reasoning loop makes benign but unlimited API calls. Standard API rate limits, designed for human-paced usage, fail under agentic load conditions. Organizations must implement a secondary circuit-breaker layer — separate from standard rate limits — that enforces absolute ceiling constraints on agent execution time, API call count per session, and cumulative cost per run. The kill switch is not a metaphor; it is a technical requirement.
Mistake 4 — No Human Escalation Path
Bounded autonomy AI without a defined human escalation path is half an architecture. Every agent deployment must answer two questions before going live: what conditions trigger escalation to human review, and who is accountable for reviewing and acting on that escalation within what timeframe? Agents that encounter decisions outside their defined operational perimeter must have a documented path to surface those decisions to a human with both the authority and the context to resolve them. Agents that fail silently or proceed anyway are not bounded — they are unbounded with better documentation.
How to Build Safe Agentic Systems: The Bounded Autonomy AI Architecture Stack
A production-grade bounded autonomy AI architecture is not a single control — it is a layered stack of interdependent enforcement mechanisms. Each layer provides a different class of protection, and the stack is only as strong as its weakest layer. The following five-layer architecture represents the 2026 standard for enterprise agentic deployments.
| Layer | Component | Function | Trust Model |
| L1 — Permission | Least-Privilege API Scoping | Hard-code read/write/execute permissions per agent role. Enforced at infrastructure, not prompt level. | Zero Trust — default deny |
| L2 — Isolation | Secure Sandbox Environment | Isolate agent workflows by function. No cross-workflow data access without explicit authorization. | Compartmentalized |
| L3 — Circuit Breaker | Rate + Cost + Time Limits | Secondary enforcement layer beyond standard API limits. Absolute ceiling on calls, cost, and execution time per session. | Deterministic override |
| L4 — Escalation | Human-in-the-Loop Gates | Defined conditions triggering human review before execution. Named accountable reviewer with SLA. | Human authority |
| L5 — Observability | Immutable Audit Trail | Every tool call, decision node, and output logged with timestamp, agent ID, and reasoning trace. Tamper-evident. | Retrospective accountability |
Layer 1 — Least-Privilege API Scoping (The Non-Negotiable Foundation)
Every bounded autonomy AI deployment begins with a formal permissions matrix that maps each agent role to the minimum set of API capabilities required for that role’s tasks. This matrix is implemented as hard technical constraints — not policy documents — enforced by the middleware API layer that sits between the agent and every downstream system it interacts with.
Practical implementation steps:
- Create a separate service account for each distinct agent role — never share credentials across agents with different task profiles
- Implement schema-level read-only locks on all data sources the agent accesses for retrieval tasks
- Use separate write-enabled credentials for agents with modification tasks, scoped to the minimum schema subset required
- Rotate agent credentials on a defined schedule — treat AI agent credentials with the same lifecycle management as privileged human user credentials
- Log every credential use — agent API calls should generate the same audit events as privileged human user actions
Layer 2 — Secure Sandbox Isolation
Agent workflows must be isolated from each other based on their function and risk profile. A customer support agent must not have access to the data or tools of a financial processing agent, even if both are running on the same underlying model. Sandbox isolation prevents lateral movement — the ability of a compromised or malfunctioning agent to affect adjacent workflows.
The 2026 joint cybersecurity guidance specifies that agentic systems should receive dedicated non-human identities with bounded permissions and revocable credentials. Their memory and tool outputs must be treated as security-relevant artifacts — not trusted inputs that can be passed unchecked to downstream systems or other agents in a multi-agent chain.
Layer 3 — Circuit Breaker Architecture
The circuit breaker layer provides absolute ceiling enforcement on agent resource consumption, independent of standard API rate limits. Standard rate limits are designed for human-paced system usage — they are structurally inadequate for agentic load patterns, where a single agent session can generate thousands of API calls in minutes.
Circuit breaker parameters must be defined per agent deployment:
- Maximum API calls per session — hard ceiling, not a soft warning threshold
- Maximum execution time per session — agent sessions exceeding the ceiling are terminated, not paused
- Maximum cumulative cost per session — critical for consumption-priced APIs where runaway agents generate unbounded charges
- Anomaly detection threshold — call patterns deviating from baseline by a defined percentage trigger automatic suspension pending human review
Layer 4 — Human-in-the-Loop Design Patterns
Human oversight is not the same as human awareness. An executive dashboard showing agent activity is awareness — it is not oversight. Bounded autonomy AI requires human-in-the-loop design: structured decision points at which agents surface specific categories of decisions to named humans with the authority and context to resolve them, before execution proceeds.
The HITL design must answer four questions for every agent deployment:
- What specific decision categories trigger mandatory human review before execution?
- Which human role is accountable for each decision category, by name and title?
- What is the SLA for human response — minutes, hours, or days — depending on the urgency of the workflow?
- What happens when the accountable human is unavailable — is there an escalation chain, and does the agent pause or proceed with reduced capability?
Leading organizations in 2026 are deploying what researchers at MachineLearningMastery.com term governance agents — dedicated AI systems that monitor other AI agents for policy violations and anomalous behavior. This represents a more scalable approach to HITL oversight at enterprise scale than purely manual review processes.
Layer 5 — Immutable Audit Trail and Observability
Agentic AI observability is not a monitoring tool — it is the control plane that makes autonomous behavior governable. Every bounded autonomy AI deployment must generate a tamper-evident record of every tool call, decision branch, reasoning step, and output, with sufficient detail to reconstruct exactly what the agent did, why, and what the consequences were.
The Arthur.ai 2026 Agentic AI Observability Playbook defines the minimum observability standard: OpenTelemetry-first pipelines enabling vendor-agnostic audit trail capture, native agent monitoring integrated into the agent framework rather than bolted on externally, and compliance-mapped logging that connects agent behavior records to regulatory audit requirements.
Bounded Autonomy AI: The Four-Stage Autonomy Model for Enterprise Deployment
Not all agent tasks require the same level of human oversight. Bounded autonomy AI architecture should implement a staged autonomy model that calibrates human involvement to the risk profile of each task category — enabling efficiency where risk is low while maintaining strict human control where risk is high.
| Stage | Name | Who Acts | Trigger to Advance | Risk Threshold |
| S1 | Task Automation | Human acts; AI assists | Consistent accuracy + audit trail established | Low — read only, no state change |
| S2 | AI-Assisted Operations | AI recommends; Human approves before execution | 90%+ accuracy rate; governance agent deployed | Medium — reversible state changes only |
| S3 | Supervised Autonomy | AI executes within guardrails; Human monitors | Circuit breaker + HITL gates operational; compliance audit passed | High — irreversible actions require L4 escalation |
| S4 | Governed Autonomy | AI executes; Human reviews post-hoc via observability | Full L1–L5 stack operational; regulatory compliance confirmed | Critical — reserved for low-stakes, high-volume, fully audited workflows |
The critical governance principle: agent permissions must never exceed those of supervising humans. An AI agent executing procurement decisions cannot hold higher authorization than the human procurement officer it is assisting. This principle, stated explicitly in the 2026 joint agentic AI governance framework, prevents agents from accumulating privileges that bypass organizational authorization structures.
Human Oversight in Enterprise Agentic AI: Design Principles for 2026
The framing of human oversight is shifting fundamentally in 2026. The narrative is moving away from treating human-in-the-loop as an acknowledgment of AI limitations toward recognizing it as a design choice that enables enterprises to deploy agents in progressively higher-value scenarios. Leading organizations are designing Enterprise Agentic Automation — a model that combines dynamic AI execution with deterministic guardrails and human judgment at key decision points.
This reframing is not semantic. It has direct architectural consequences. When human oversight is treated as a limitation acknowledgment, organizations minimize it as quickly as possible — removing HITL gates as adoption matures, reducing review frequency, and lowering escalation thresholds. When human oversight is treated as a governance enabler, organizations design it into the architecture permanently and tune it based on risk evidence rather than convenience.
The Objective Drift Problem
TechRadar’s 2026 analysis of agentic AI governance identifies objective drift as one of the most underappreciated risks in long-running agent deployments: the tendency of semi-autonomous systems to deviate from their intended goals over time, particularly in multi-step workflows where the agent’s internal representation of the task objective can subtly shift through iterative reasoning steps.
Human oversight is the primary mechanism for detecting objective drift before it produces consequential errors. Governance frameworks that rely solely on automated monitoring for drift detection will miss the class of drift that appears technically correct at each individual step but produces a systemically wrong outcome. Human reviewers with business context can identify this class of error; automated systems generally cannot.
The Governance-as-Enabler Principle
The mature governance frameworks emerging in 2026 share a common insight: governance is not a constraint on agent capability — it is the mechanism by which organizations earn the organizational trust to expand agent capability into higher-value scenarios. An organization that has deployed bounded autonomy AI with robust HITL gates, immutable audit trails, and circuit breakers can extend agents into new domains with confidence, because the failure modes of those domains are already handled by the existing governance architecture.
Organizations that bypass governance to accelerate deployment are not moving faster — they are borrowing from a future liability that will compound until it is paid in the form of an incident.
Conclusion: Bounded Autonomy AI Is the Competitive Architecture of 2026
Bounded autonomy AI is not a safety compromise — it is the architecture that makes enterprise-scale agentic deployment possible. Organizations that treat human oversight as a liability and governance as overhead are not moving faster toward autonomous AI; they are accumulating the conditions for an incident that will set their AI program back further than any governance investment could have.
The evidence from the 2026 research landscape is unambiguous: bounded autonomy, deterministic guardrails, human-in-the-loop design, and comprehensive observability are the characteristics that distinguish agents running safely in production from agents generating risk in production. Gartner’s projection of 40% enterprise AI agent penetration by year-end 2026 means that the governance architecture decision is not a future consideration — it is a current engineering requirement.
Implementation priorities for engineering and executive teams:
- Conduct a permissions audit of every deployed AI agent this month — identify any agent holding write-access, database credentials, or API permissions beyond task necessity, and remediate immediately.
- Implement the five-layer bounded autonomy stack before expanding any existing agent to new use cases — do not extend capability before extending governance.
- Define the four HITL design questions for every agent deployment: decision trigger categories, accountable reviewer role, response SLA, and unavailability protocol.
- Deploy circuit breaker controls with absolute ceilings on calls, cost, and execution time for every production agent — treat runaway agent sessions as a defined risk category, not an edge case.
- Build an immutable audit trail for every agent action — not as a compliance requirement, but as the control plane that makes autonomous behavior governable and improvable.
- Stage your autonomy advancement deliberately — do not promote an agent from Stage 2 to Stage 3 without explicit evidence that the governance criteria for Stage 3 are met.
The enterprises building bounded autonomy AI infrastructure today are building the foundation for governed autonomy at scale. The enterprises skipping governance to ship faster are building the conditions for their most public AI failure.
Frequently Asked Questions (FAQs)
Q1: What is bounded autonomy AI?
Bounded autonomy AI is the architectural principle of hard-coding deterministic guardrails around probabilistic AI models to ensure that agents operate within strict, unbreakable operational perimeters. It combines zero-trust permission architecture, least-privilege API scoping, circuit breaker controls, human-in-the-loop approval gates, and immutable audit trails to prevent AI agents from taking unauthorized, unintended, or cascading actions. The core insight is that AI model safety and deployment safety are different problems — bounded autonomy AI addresses deployment safety by making the consequences of model errors perfectly bounded.
Q2: Why do bounded autonomy implementations fail in practice?
The most common failure modes are: treating API access as binary rather than task-scoped; relying on model instructions (system prompts) for safety enforcement rather than infrastructure-layer constraints; ignoring rate and cost loop risks from agents entering infinite execution cycles; and failing to define a human escalation path for decisions outside the agent’s operational perimeter. The result is governance documentation that describes constraints which the deployed system does not technically enforce — creating the illusion of safety rather than the reality of it.
Q3: What is the least-privilege principle for AI agents?
The least-privilege principle applied to AI agents means that every agent receives the minimum set of permissions required for its defined tasks — and no more. This is implemented as hard technical constraints enforced by an intermediate middleware API, not as policy instructions to the model. If an agent needs to read customer records, it receives read-only API credentials scoped to that schema. It does not receive write access, delete access, or credentials that extend to adjacent data systems. Agent permissions must also never exceed those of the supervising human roles the agent is assisting.
Q4: How do you design a kill switch for an AI agent?
An AI agent kill switch is implemented as a circuit breaker at the infrastructure layer — not as a prompt instruction. It requires three components: a hard ceiling on API calls per session (separate from standard rate limits), a hard ceiling on execution time per session, and a hard ceiling on cumulative cost per run. When any of these thresholds is reached, the agent session is terminated rather than paused, and the termination is logged with full context for human review. Additionally, anomaly detection monitoring agent call patterns against a baseline should trigger automatic suspension when deviations exceed a defined threshold, pending human investigation.
Q5: What is human-in-the-loop (HITL) in agentic AI systems?
Human-in-the-loop in agentic AI systems refers to structured decision points at which agents surface specific categories of decisions to named human reviewers with appropriate authority, before execution proceeds. HITL is not human awareness of agent activity — it is human authorization for specific action categories. A well-designed HITL architecture defines: which decision categories trigger mandatory review, which human role is accountable for each category, the response SLA for that review, and the agent behavior when the accountable reviewer is unavailable. HITL gates should be built into the agent architecture as permanent infrastructure tuned by risk evidence, not removed as adoption matures.
Q6: What is objective drift in agentic AI and how does bounded autonomy address it?
Objective drift is the tendency of semi-autonomous AI agents to gradually deviate from their intended goals over the course of multi-step workflows — where the agent’s internal representation of the task objective shifts subtly through iterative reasoning steps, producing a systemically wrong outcome despite each individual step appearing technically correct. Human oversight through HITL design is the primary mechanism for detecting objective drift, because human reviewers with business context can identify outcome-level correctness in ways that automated monitoring systems generally cannot. Comprehensive observability — logging reasoning chains, not just outputs — also enables retrospective drift detection.
Q7: How does bounded autonomy AI relate to the NIST AI Risk Management Framework?
The NIST AI Risk Management Framework’s four functions — Govern, Map, Measure, Manage — map directly to bounded autonomy AI architecture requirements. The Govern function establishes the organizational accountability structures and risk tolerance policies that define operational perimeters. Map identifies and categorizes the specific risk categories for each agent deployment, including privilege risks and behavioral risks. Measure implements the technical monitoring and observability infrastructure that quantifies those risks in production. Manage activates the circuit breaker, escalation, and response protocols when risks are detected. The NIST AI Agent Standards Initiative explicitly frames secure agentic systems around least privilege, human oversight, and accountability — the core components of bounded autonomy architecture.
Q8: What is a governance agent and how does it support bounded autonomy?
A governance agent is a dedicated AI system deployed specifically to monitor other AI agents for policy violations and anomalous behavior — rather than relying entirely on human review for oversight at scale. Governance agents implement automated policy enforcement checks against predefined rules, flag anomalous tool call patterns that deviate from baseline behavior, and surface potential violations to human reviewers with full context for investigation. As enterprise agentic deployments scale beyond what manual review can cover, governance agents provide a scalable first-line oversight mechanism that augments rather than replaces human accountability. They represent the operationalization of bounded autonomy at enterprise scale.
| About the Author Waqas Raza is a Technical SEO Specialist and Digital Strategist with a focus on B2B SaaS architecture. He writes for enterprise technology leaders, AI architects, and engineering teams navigating agentic AI deployment, governance, and safe system design. vitaloralife.com |